March 20, 2026
Hyperbolic Recurrent State-Space Model (H-RSSM)
Personal research on hyperbolic latent spaces for learning hierarchical representations.
Status: Work in progress. This is ongoing research.
All results below are preliminary and, except where stated, single-seed (because of computional limitation). Multi-seed variance is reported only for the comparison in Experiment 3.
Project Overview
World models for RL learn a latent representation of the environment and reason entirely within it. In practice, that latent space is almost always Euclidean—which works fine, but isn’t optimal for everything. When you’re dealing with hierarchical structure (trees, nested sub-goals, part-whole relationships), hyperbolic geometry is theoretically superior: it can embed trees with bounded distortion in constant dimension, whereas Euclidean space simply can’t. The problem is computational. The natural distribution on lacks a closed-form normalising constant, which makes the KL term in the ELBO untractable at training speed.
That’s what I set out to fix. I introduce the Horospherical Gaussian (): a distribution family over the upper half-space model of hyperbolic space where the normalising constant, KL divergence between pairs, and reparameterised sampler all have closed-form expressions in , matching the cost of a standard Gaussian RSSM. It’s geometrically motivated but not geodesically exact; I characterise the approximation error explicitly.
On a synthetic -ary tree MDP, the prior does produce depth alignment (), but it’s modest and the reconstruction MSE stays well above the observation noise floor. The most interesting empirical result is that alignment extends monotonically to depths the model never saw during training (). But it doesn’t hold up. Under longer training, the hyperbolic drops from to while the Euclidean baseline stays flat. Every architectural tweak I tried to strengthen the signal—decoupled KL weights, geometry-aware decoder, action-conditioned prior—either collapsed the representation or got absorbed by the reconstruction loss. This write-up documents what worked, what didn’t, and where I’m still uncertain.
Key findings at a glance
- Dimensional efficiency (consistent with Sarkar (2011)). reaches , statistically indistinguishable from at . But is essentially flat across dimensions for both models, so the result is only consistent with the capacity advantage of and not a clear demonstration of the theorem.
- Out-of-distribution depth ordering. Trained on depths 0–5, the standard model correctly ranks depth 6–7 nodes it never saw (). The corresponding action-prior variant, whose bias parameters collapse to , inverts the OOD ordering ().
- Erosion under extended training. At 50k steps, for drops from ; the Euclidean baseline stays at . The geometric inductive bias is not self-reinforcing under the current (Euclidean) reconstruction loss.
Table of Contents
- Hyperbolic Latent Spaces
- The Technical Obstacle: Intractable KL Divergences
- The Horospherical Gaussian
- Experimental Setup
- Results
- Group A — Baseline claim: does HG induce depth alignment?
- Group B — Attempts to strengthen the signal (all fail or trade off)
- Group C — Where hyperbolic geometry pays off
- Experiment 8: Dimensional Efficiency — vs
- Experiment 9: OOD Depth Generalisation
- Discussion
- Assumptions and Limitations
- Code and Reproducibility
- References
- Appendix: Derivations
1. Hyperbolic Latent Spaces
1.1 Why Hyperbolic Geometry?
World models like DreamerV3 or IRIS jointly learn a compact latent representation of the environment and a transition kernel over it. The agent reasons over latent states, not observations. So the geometry of that latent space shapes everything it can represent and predict.
In practice, we always choose Euclidean geometry: . It’s the default because it’s computationally convenient.
But many environments have hierarchical structure. Think of an agent navigating nested sub-goals in a grid world, manipulating objects with part-whole relationships, or exploring a maze with branches. In all these cases the state space is tree-like. States multiply exponentially with depth. Euclidean space has polynomial volume growth: the volume of a ball of radius grows as . That means you can’t fit exponential node counts without distorting distances badly. You’d need dimensions to embed a tree of nodes with acceptable distortion.
Hyperbolic space is different. It has exponential volume growth: a ball of radius in has volume , exactly matching tree structure. Sarkar (2011) showed that any tree of nodes embeds into with bounded distortion—constant, independent of —in just 2 dimensions. In Euclidean space, you’d need .
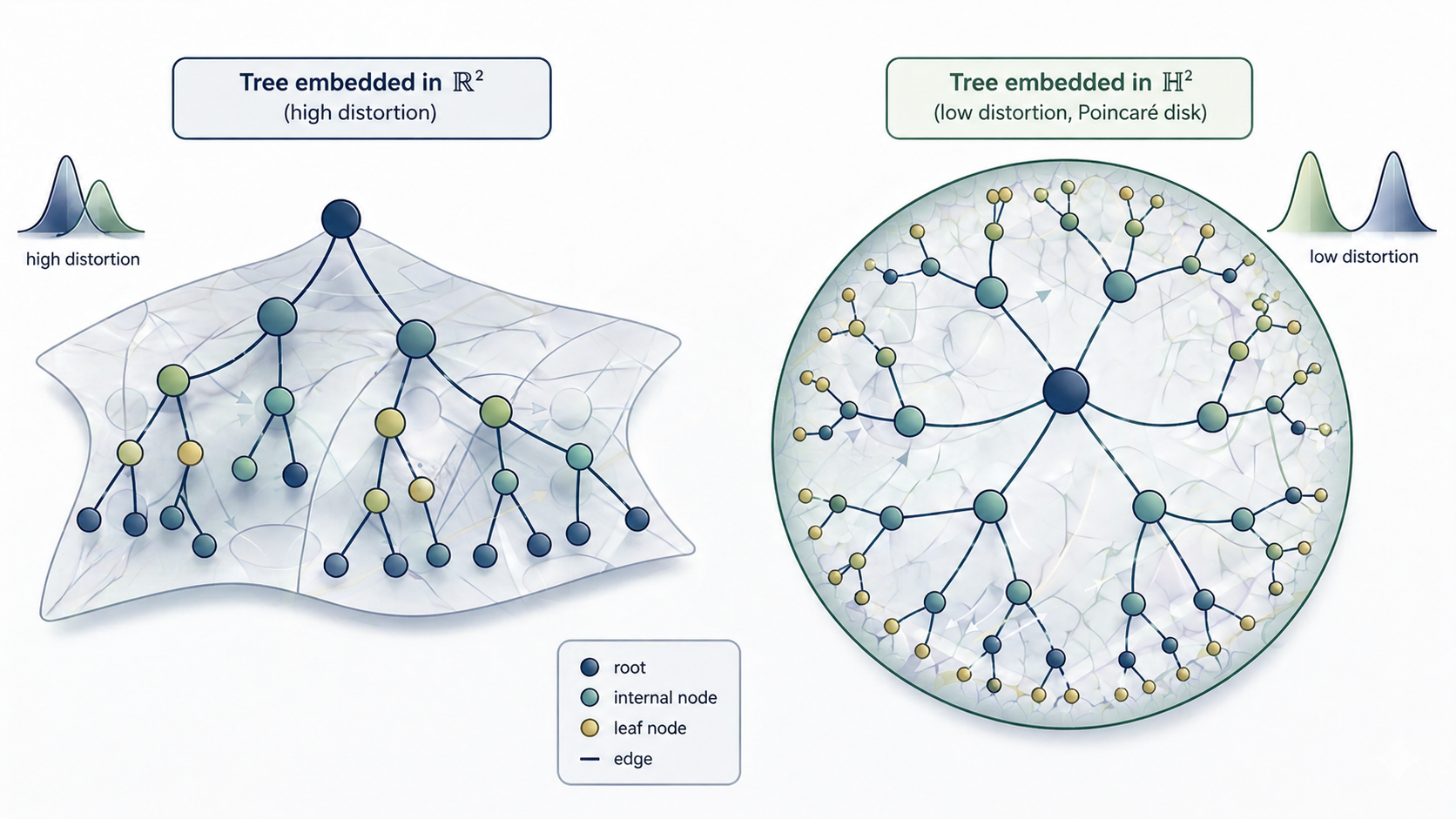
Trees embed efficiently in hyperbolic space () with bounded distortion, compared to polynomial distortion in Euclidean space ().
1.2 Embedding in
Early work on hyperbolic geometry in ML focused on static embeddings: you have a dataset with known hierarchical structure (a taxonomy, knowledge graph, phylogeny), and you learn to map nodes to while preserving distances. Nickel & Kiela’s Poincaré embeddings are the classic example. They showed that WordNet hierarchies embed in with far less distortion than any Euclidean baseline at the same dimension.
The insight is elegant. The Poincaré ball model with metric naturally places the root near the origin (where space is sparse) and leaves near the boundary (where space is exponentially dense). Depth in the hierarchy maps directly to distance from the center.

Poincaré disk with a small tree embedded. Root at center, leaves near boundary
But that’s learning from ground truth. In a world model, you don’t know the structure ahead of time. You have to infer it from observations alone. The embedding becomes a posterior : a distribution over that changes at each timestep, learned end-to-end from raw data.
1.3 Learning a Model Inside
That’s where the problems start. Moving from offline static embeddings to a learned generative model introduces three tight constraints, all rooted in the same issue: there’s no tractable Gaussian-like distribution on . Specifically:
- (i) no standard family has a closed-form density with respect to the Riemannian volume
- (ii) without that, the KL in the ELBO has to be estimated by Monte Carlo
- (iii) the reparameterisation trick doesn’t carry over from
Distributions on . A VAE-style world model needs a prior and a posterior , both on . The natural choice is the Riemannian Normal , but it has no closed-form normalising constant for . Other proposals exist: wrapped normals (Nagano et al., 2019) are computationally heavy; pseudo-hyperbolic Gaussians sacrifice geometric fidelity. None of them are simultaneously tractable, geometrically sound, and fast enough for RL training.
KL divergences. Training requires computing at every gradient step. Without a closed form, you resort to Monte Carlo estimation, which kills throughput when you need fast ELBO evaluations. This is why hyperbolic world models haven’t really taken off.
Reparameterisation. You need to backprop through . On a Riemannian manifold, the standard Euclidean reparameterisation trick doesn’t apply directly. Exponential-map approaches exist but blow up numerically near the boundary of the Poincaré ball.
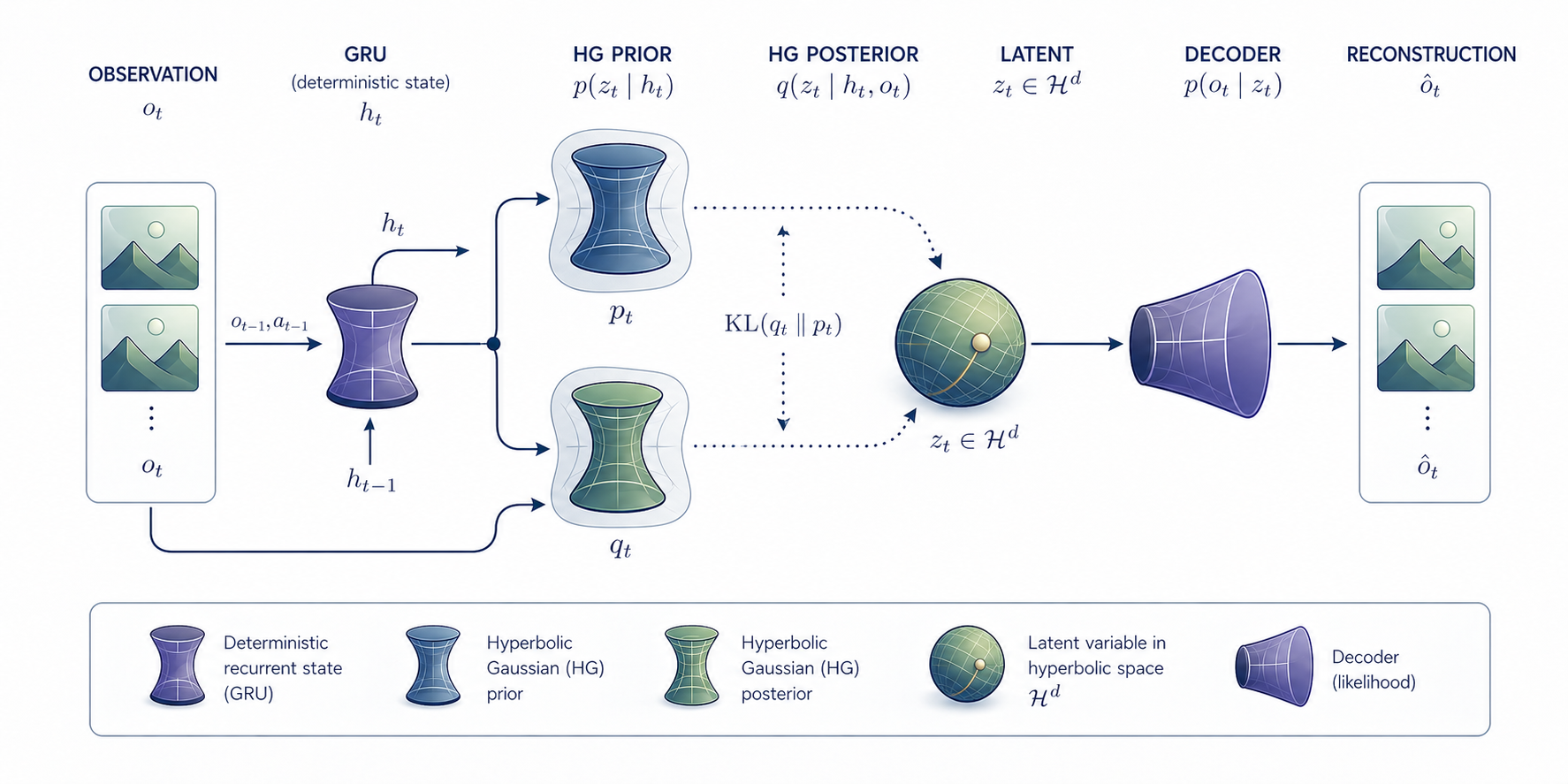
Full model pipeline
My approach solves all three by using the upper half-space model and introducing a new distribution: the Horospherical Gaussian. It’s designed so the KL is exactly tractable in , sampling is exact, and the geometry holds to leading order.
2. The Technical Obstacle: Intractable KL Divergences
World models are trained by maximising the ELBO:
In the Euclidean case both prior and posterior are Gaussian and the KL has a closed form in . On the natural candidate is the Riemannian Normal, but its normalising constant is the integral that blocks the whole approach:
For every this integral has no closed form. KLs between Riemannian Normals therefore require Monte Carlo estimation, which is far too slow for the per-step ELBO evaluations we need during training. A like-for-like MC estimator would demand a large sample budget per step compared with the arithmetic of the closed-form alternative I develop below.
This is the problem I set out to fix first.
3. The Horospherical Gaussian
3.1 Construction
I work in the upper half-space model of hyperbolic space, using horospherical (log-height) coordinates:
The metric is
and the Riemannian volume form is
This is the same geometry as the usual upper half-space coordinates with after the change of variables , (see A.6 for the derivation). The coordinate is the Busemann coordinate (signed distance to the ideal boundary ) and is the fibre coordinate (the lateral position within a level set). I prefer this model to the Poincaré ball because additive updates are globally well-defined and avoid the boundary singularities that can destabilise Möbius-based implementations.
Horospherical Gaussian. Fix , , , . I define the distribution with density w.r.t. by
The conditional variance is the unique scaling under which the two cancellations below occur.
3.2 Tractability: the two cancellations
Two elementary cancellations are what make the family tractable.
Cancellation 1 (normalising constant). If you integrate out the -component at fixed you pick up a factor that exactly cancels the in the volume form. The normalising constant evaluates to
independent of and (full derivation in A.1).
Cancellation 2 (drift moment). The tower property gives
Both cancellations are exact and together they make the closed-form KL possible.
Closed-form KL. Combining the cancellations yields a closed-form KL between two distributions (derivation in A.2):
All three terms are exact and total computation is . The drift term follows from the MGF identity . I validated the full expression against a large-sample GPU Monte Carlo estimate: relative error 0.005%.
Reparameterisation. Sampling is exact and straightforward to implement:
Note the coupling of to through the factor : it is exact and must be preserved in autograd (see A.3).
3.3 Cost of tractability: is not the Riemannian Normal
The is a tractable approximation rather than the geodesically exact Riemannian Normal. The leading-order discrepancy (see A.4) is
For and this term evaluates to approximately . Whether this approximation error matters in practice is one of the empirical questions the experiments address.
The trade-off summarised:
| Riemannian Normal | Wrapped Normal | ||
|---|---|---|---|
| Closed-form KL | ✓ () | ✗ | partial |
| Exact reparameterisation | ✓ | ✗ | ✓ (exp-map) |
| No boundary singularities | ✓ (half-space) | — | ✗ (Möbius) |
| Geodesic exactness | leading-order | ✓ | approximate |
4. Experimental Setup
4.1 Hypotheses under test
I’m testing three concrete claims, in order:
- H1 (alignment). Training on the ELBO alone is enough for to align its Busemann coordinate with ground-truth depth.
- H2 (capacity). reaches a given level of depth alignment at lower dimension than a Euclidean Gaussian (a sample-efficiency consequence of Sarkar’s theorem).
- H3 (extrapolation). The alignment creates an ordering that extends monotonically to depths never seen in training.
4.2 Environment
I use a -ary tree MDP: a rooted tree with branching factor and depth . Each node has a known depth and a fixed observation generated by mixing random depth and branch embeddings:
The embeddings and are not given to the model. It only sees and has to infer the structure from sequential transitions alone. For the main experiments I use , , which gives 1365 nodes. That suggests a crossover around : below that scale you would expect a Euclidean model to start losing its advantage and struggle with the tree hierarchy relative to .
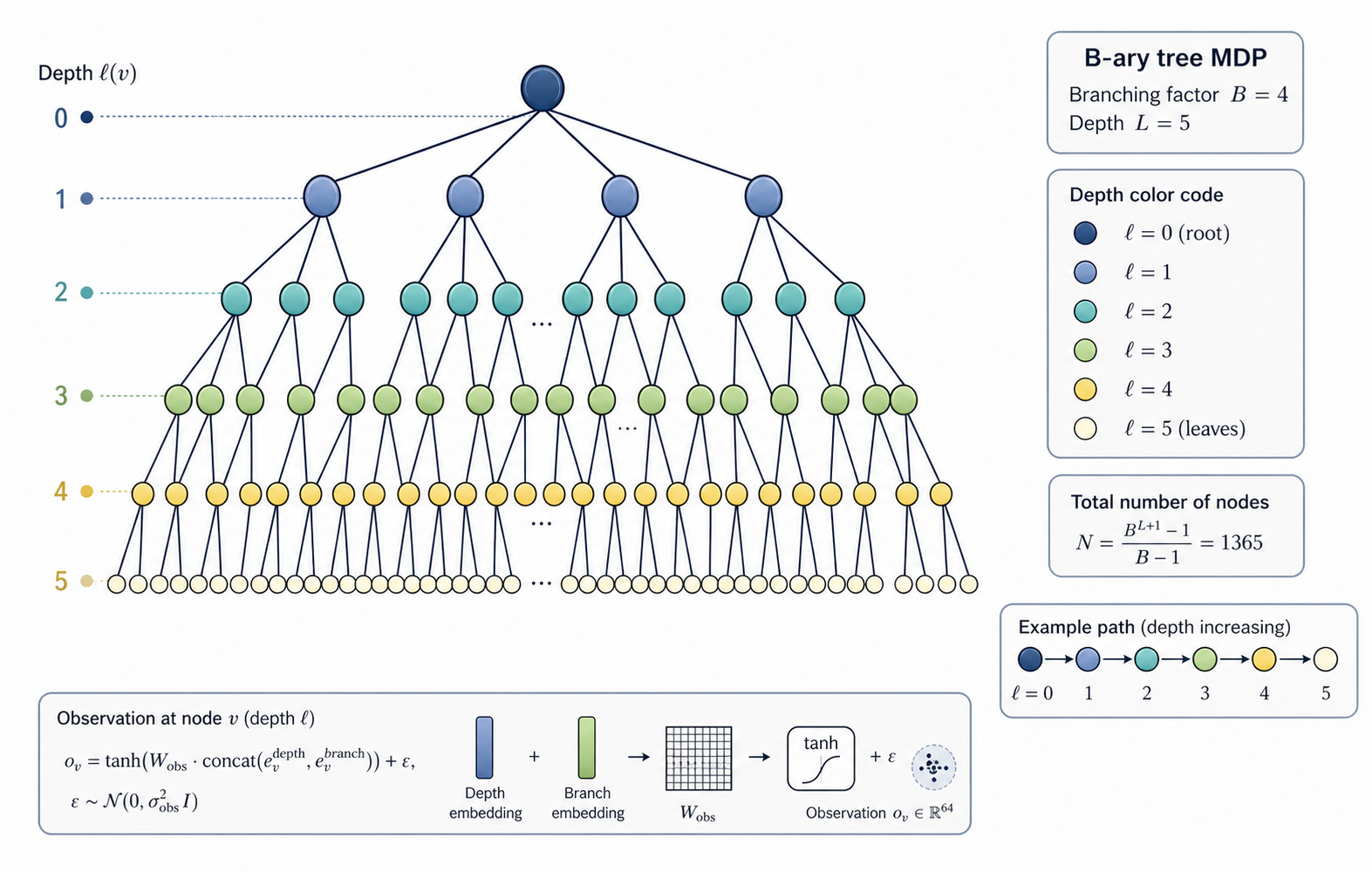
B-ary tree MDP
The observation noise creates a reconstruction MSE floor: if the decoder perfectly reconstructed the clean mean, the residual error from noise alone would be . In my code, , which means the per-dimension floor is . I use this later to interpret whether my model’s reconstruction is actually learning anything or just hitting the noise floor.
4.3 Model
I build a sequential world model with GRU recurrence. The prior and posterior are either distributions on (the hyperbolic model) or Gaussians on (the Euclidean baseline). Everything else is held equal: same dimensions, same decoder architecture, same parameter count. This makes the comparison fair: vs .
I don’t run any existing hyperbolic-VAE baselines (wrapped normal, Poincaré VAE). This is a real gap (see §7), so the main comparisons in this work are just vs Euclidean Gaussian.
The code path is the same order of complexity as the Euclidean baseline, but I haven’t included a wall-clock benchmark to prove it. That’s something I should add.
4.4 Metrics
I measure four things:
- Reconstruction MSE on held-out test trajectories - interpreted relative to the floor above.
- Spearman — correlation between and ground-truth depth (hyperbolic only).
- Linear probes — logistic regression from alone to depth, and from alone to branch index at depth 1, separating representation quality from reconstruction quality.
- Gradient attenuation - measuring the amplification of -gradients through the reparameterisation coupling.
4.5 Reporting convention
Except where I explicitly say otherwise, every table below shows a single training run per configuration. Computing limits meant I couldn’t afford many seeds. The only multi-seed estimate is Experiment 3 (5 seeds), which gives me a variance band of roughly in . If you see a difference in smaller than 0.05 between two runs, it’s probably within that noise band and shouldn’t be trusted as a real effect.
5. Results
I’ve grouped the experiments into three blocks:
- (A) the baseline claim that induces depth alignment
- (B) four attempts to strengthen that signal, each one either trading off against MSE or collapsing the prior
- (C) the two findings where hyperbolic geometry does provide something Euclidean does not: dimensional efficiency and out-of-distribution depth ordering
Group A - Baseline claim: does HG induce depth alignment?
Experiment 1: τ Spontaneously Encodes Depth
Question. Trained purely on the ELBO with no depth supervision, does the Busemann coordinate end up correlated with ground-truth depth?
Setup. Single seed, , standard prior/posterior.
Result. The hyperbolic model achieves on a single run. The Euclidean baseline achieves at (best principal component, the strongest possible PCA baseline). The difference is small and must be read together with Exp 3, which quantifies seed variance at . also shows a positive correlation with depth without supervision. Whether this constitutes a robust “advantage” over the Euclidean baseline is a question Exp 3 addresses directly.
The drift term penalises fibre mismatch less when is larger. So if deeper nodes usually have more fibre mismatch, the model is pushed toward larger for those nodes. This depth-to-fibre-mismatch link is only a hypothesis here; we did not measure it directly.
Experiment 2: Reconstruction vs Representation
Question. Do hyperbolic latent dimensions improve either reconstruction or representation quality?
Setup. Sweep , 15 000 training steps, KL warmup, single seed.
| MSE hyp | MSE euc | Probe | Probe branch | |||
|---|---|---|---|---|---|---|
| 2 | 0.405 | 0.405 | 1.04 | +0.321 | 0.68 | — |
| 4 | 0.405 | 0.405 | 1.64 | +0.266 | 0.68 | — |
| 8 | 0.405 | 0.405 | 1.07 | +0.285 | 0.68 | — |
| 16 | 0.406 | 0.405 | 1.04 | +0.306 | 0.68 | — |
| 32 | 0.405 | 0.405 | 0.73 | +0.277 | 0.68 | — |
Reconstruction (MSE). Both models stay at across every dimension, differing by . With , these are far above the noise floor, so what I’m comparing here is model reconstruction quality, not noise saturation.
Representation. ranges 0.266–0.321 across , essentially flat within seed noise. The depth probe sits flat at 0.68 across all dimensions. This could mean one of two things:
- (i) the depth signal in genuinely caps at the probe’s capacity,
- (ii) or the logistic-regression probe is saturated by the tree’s depth class imbalance. My current data doesn’t distinguish between them.
The branch probe never converges. Experiment 4 revises my interpretation: it’s a regularisation artefact, not a structural property of the fibre coordinate.
Reconstruction MSE vs dimension. Euclidean (orange) stays flat; hyperbolic (blue) moves within a negligible range. Both remain far above the observation-noise floor.
Linear probe accuracy. Blue circles: depth from at 0.68, flat across . The branch probe did not converge.
Experiment 3: Geometric Inductive Bias Across Seeds
Question. Is that modest hyperbolic advantage in Exp 1 larger than seed noise, or is it just a fluke?
Setup. Both models at , 2000 steps, 5 seeds each. Computing limits kept me from running more. I logged Spearman between and depth every 100 steps (hyperbolic), and best-PCA across all components for Euclidean (the strongest possible baseline). Shaded regions show ±1σ across seeds.
Mean at step 2000: hyperbolic , Euclidean . The two are indistinguishable in both mean and variance. The Euclidean model starts with high accidental alignment (best-PC cherry-picked from random init), then settles to the same regime as hyperbolic. The hyperbolic trajectory starts lower but rises from step 0.
Within the noise from this experiment, hyperbolic and Euclidean reach the same depth-alignment magnitude at step 2000. What differs is the trajectory, not where they end up. So the honest headline for the depth-alignment claim is: Exp 1’s single-seed vs sits right within the noise band.
What this does not show. I report absolute values of , which hides the sign. A geometric inductive bias is only as strong as the sign consistency across seeds. Without checking the sign across all five seeds, I can’t verify the “consistent push toward deeper = higher ” story directly, even though the mechanism supports it.
The drift term penalises fibre mismatch in proportion to , which creates a directional gradient pushing larger for nodes that diverge from the prior. But the signal-to-noise threshold for reconstructing tree-like structure (Kesten–Stigum, 1966) is not met at , so the maximum attainable stays capped regardless of geometry.
Group B - Attempts to strengthen the signal (all fail or trade off)
Below I try four different architectural levers to amplify the depth-encoding bias. Each one fails or introduces a matching cost elsewhere.
Experiment 4: Separate KL Weights β_τ / β_b
Question. In Experiments 1–3 I used a single to weight all KL terms equally. But the fibre KL is weighted by and dominates the height KL at large . What if I decouple the weights ( for the height term, for the fibre and drift terms) to improve the depth signal without hurting reconstruction?
Setup. Single seed, , sweep over and .
| MSE | Probe | |||
|---|---|---|---|---|
| 1.0 | 1.0 | 0.405 | +0.338 | 0.669 |
| 1.0 | 0.1 | 0.363 | +0.306 | 0.515 |
| 1.0 | 0.01 | 0.068 | +0.016 | 0.510 |
| 2.0 | 0.1 | 0.363 | +0.304 | 0.524 |
Reducing reveals a sharp trade-off. At , MSE drops 11% (0.405 → 0.363) with only marginal loss in : a clear MSE vs depth trade, but still far above the noise floor. At , MSE collapses to 0.068 but collapses to 0.016: the model stops encoding depth and just learns a trivial reconstruction. Doubling to 2.0 with doesn’t recover the depth signal ().
What this reveals about Exp 2’s branch null. The -probe never converged in Exp 2. Here I see that the fibre KL wasn’t suppressing in a way that encoded branch structure elsewhere: it was just acting as a regulariser that prevents MSE collapse. Remove it and MSE drops but the latent becomes unstructured. So I should revise my original reading of the branch-probe failure from “structural constraint” to “regularisation artefact”.
What this does not show. The MSE drop is tempting, but moves the wrong way. The trade-off is real; the best setting is just the unweighted default.
Experiment 5: Longer Training (50k steps)
Question. Does the depth alignment from Exp 1–3 strengthen with more training, stabilise, or erode?
Setup. , 50 000 steps (3× longer than Exp 2), single seed, direct comparison to the 15k numbers.
| Model | MSE (15k) | MSE (50k) | (15k) | (50k) |
|---|---|---|---|---|
| Hyperbolic | 0.406 | 0.404 | +0.306 | +0.200 |
| Euclidean | 0.405 | 0.404 | +0.275 | +0.276 |
MSE doesn’t move for either model. The hyperbolic erodes from 0.306 to 0.200, falling below the Euclidean baseline at 0.276. This erosion is specific to HG, it’s not a generic over-training effect.
The drift term creates a depth-aligning gradient early in training, but the (Euclidean) MSE reconstruction objective doesn’t reinforce it. As optimisation continues, drifts toward whatever value minimises reconstruction, which isn’t necessarily depth-correlated. The Euclidean model, lacking any geometric inductive bias to lose, settles into a stable local minimum.
This same erosion mechanism (geometric structure in the prior being absorbed by reconstruction pressure) shows up again as an explicit parameter collapse in Exp 7.
What this does not show. Single seed; I don’t know the magnitude of erosion across different seeds.
Experiment 6: Geometry-Aware Decoder
Question. The decoder in all previous experiments receives as a flat vector and is not told that is a Busemann coordinate. If I give the decoder explicit geometric features, does that improve reconstruction or representation?
Setup. Augment the decoder input with (metric scaling factor) and (squared -distance in the hyperbolic metric). Single seed, .
| Variant | MSE | Probe | |
|---|---|---|---|
| Geometry-aware decoder | 0.405 | +0.270 | 0.632 |
| Standard (flat) decoder | 0.405 | +0.295 | 0.680 |
| Euclidean baseline | 0.405 | +0.287 | — |
The geometry-aware decoder does not help. It slightly worsens both (+0.270 vs +0.295) and the depth probe (0.632 vs 0.680), and it does so with no MSE improvement.
I think this is a classic representation-collapse dynamic. Exposing and directly gives the decoder a reconstruction shortcut that removes the encoder’s incentive to encode depth cleanly in . The pressure that created the structured representation is gone, and the MSE stays unchanged because both paths reach essentially the same reconstruction level.
Future work. Gating or annealing the shortcut features, for example warm-starting with flat input and slowly exposing the geometric features, might preserve the encoder pressure. I have not tested that.
Experiment 7: Action-Conditioned Prior
Question. Exp 5 showed depth alignment erodes under extended training. Can injecting action labels directly into the prior make depth alignment an explicit structural objective rather than a fragile KL side effect?
Setup. Augment the prior with an action-conditioned offset to :
where encodes the direction of the last transition (deeper / shallower / same level) and are learned scalars.
| Model | ρ @ 5k | ρ @ 15k | ρ @ 30k | ρ @ 50k |
|---|---|---|---|---|
| Standard HG | 0.080 | 0.281 | 0.271 | 0.273 |
| ActionPrior HG | 0.755 | 0.319 | 0.286 | 0.277 |
At step 5k the action prior reaches , which is an exceptional early alignment and far above the standard model’s . That advantage disappears by step 15k, and both models converge to by step 30k. The learned bias parameters collapse to near zero: , . In practice, the model learns to ignore its own structural prior.
The action prior functions as a warm-start mechanism, not a stable structural constraint. Early in training the action signal provides a strong depth gradient that initialises well. As optimisation continues, the reconstruction loss dominates and the model adapts by zeroing out the prior bias, which is the same failure mode as Exp 5 but reached faster and more visibly.
What this does not show. I have not tested whether a non-learnable action offset, with frozen and , would preserve the early alignment.
Group C - Where hyperbolic geometry pays off
Experiment 8: Dimensional Efficiency - vs
Question. Sarkar (2011) proves any finite tree embeds into with distortion converging to 1. In the learning setting, can a 2-dimensional hyperbolic latent capture depth as well as a 32-dimensional Euclidean latent?
Setup. Train each model at (where defined), 15k steps, single seed per cell.
| Model | ||||||
|---|---|---|---|---|---|---|
| 0.264 | 0.266 | 0.266 | 0.275 | 0.272 | — | |
| — | 0.264 | 0.262 | 0.265 | 0.277 | 0.071 |
Three things are true here, and only one of them is what Sarkar predicts:
- matches within noise (0.264 vs 0.277). Consistent with the capacity advantage.
- Neither model benefits from dimension. Hyperbolic is flat at 0.26–0.28 across ; Euclidean is similarly flat at 0.26–0.28 across . Sarkar predicts the hyperbolic model should beat Euclidean at matched low — that is not observed.
- collapses to 0.071. This is almost certainly an optimisation artefact (best-PC drift at high with a fixed training budget), not a capacity failure.
The honest reading is therefore: H² is not worse than R³² on this metric, and neither model is capacity-limited in the tested range. This is consistent with Sarkar’s theorem carrying over to the learning setting but does not cleanly demonstrate the predicted advantage, because both models are in a regime where added dimensions are not helping.
The flatness in is a separate, interpretable finding: all depth information in is carried by the scalar by construction; the fibre coordinates are depth-uninformative by design. Adding fibre dimensions cannot change .
What this does not show. A clean dimensional-efficiency advantage would require a setting where Euclidean grows with , so that the capacity curve is visible, while hyperbolic saturates at low . At the observation-noise and training-budget levels here, no such curve appears.
Experiment 9: OOD Depth Generalisation
Question. Does the depth ordering induced by extend to depths the model never saw in training?
Setup. Train on a deeper tree (, ) with walks restricted to depth . Evaluate separately on in-distribution nodes (depth 0–5) and OOD nodes (depth 6–7). Compare the standard to the ActionPrior variant from Exp 7.
Caveat, stated up front. The OOD depth range covers 2 levels (6, 7) versus 6 levels (0..5) in-distribution. A scalar correlation over a 2-level range is simpler than over a 6-level range and tends to give larger magnitudes. The sign and consistency of the OOD ranking are the load-bearing claims; the magnitude comparison to in-distribution is not.
| Model | in-dist (depth 0–5) | OOD (depth 6–7) |
|---|---|---|
| Standard HG | +0.334 | +0.536 |
| ActionPrior HG | +0.108 | −0.511 |
The standard model achieves . The sign is correct, the magnitude is strong, and the model has never seen depth 6 or 7 in training. The induced ordering, deeper to higher , extends monotonically beyond the training range. This is the hardest result to explain without the hyperbolic geometry, because the drift term’s penalty structure creates a ranking that comes from the KL objective rather than memorised depth values.
The ActionPrior variant inverts the OOD ordering (). This is not a small degradation, because the model actively predicts that deeper nodes are shallower. Combined with Exp 7’s bias-parameter collapse (), this suggests the ActionPrior creates a subtly distorted geometry that does not extrapolate. Structural priors that learn to zero out their own parameters can break the geometry they were meant to reinforce.
What this does not show. This is still single-seed. I have not tested whether the OOD result holds across seeds, and given Exp 3’s seed variance on in-distribution , a multi-seed replication of Exp 9 is the single most important follow-up. I also have not tested whether OOD generalisation degrades with extended training in the same way as in-distribution did in Exp 5.
6. Discussion
The strongest result in this work is Experiment 9: the standard model induces a depth ordering that extends monotonically to depths it never saw during training (), while the ActionPrior variant, whose learned bias collapses to , inverts that ordering (). The positive case is the clearest sign that the geometry is acting like a structural property of the objective rather than a memorised fit to the training set. I still need to keep the caveat from Exp 9 in mind: the OOD is computed over a 2-level depth range, so it should not be read as absolute evidence that the model is “generally better” at extrapolation.
The rest of the picture is more mixed. I summarise the evidence as honestly as I can:
| Claim | Evidence for | What’s not yet shown |
|---|---|---|
| has closed-form KL at | Derivation in §3.2 and A.2; Monte Carlo validation, relative error 0.005% | Wall-clock comparison to Euclidean Gaussian was not measured; comparison to wrapped normal was not run |
| aligns with depth without supervision | Consistent positive in Exp 1, 2, 8 | Sign consistency across seeds was not measured; mechanism (depth ↔ fibre mismatch) is hypothesised |
| Hyperbolic > Euclidean at | Exp 1 (single seed): 0.306 vs 0.275 | Exp 3 (5 seeds): 0.277 ± 0.052 vs 0.271 ± 0.054, indistinguishable. Single-seed gap is within seed noise |
| Dimensional efficiency (Sarkar, learned) | Exp 8: H² (0.264) ≈ R³² (0.277) | Both models flat across ; expected capacity curve not visible |
| Depth generalisation OOD | Exp 9: (standard HG) | Single seed; OOD depth range only 2 levels; degradation under long training untested |
| Alignment is durable | — | Exp 5: HG-specific erosion 0.306 → 0.200 at 50k; Exp 7: prior collapses to 0.0008 |
What works. The construction itself, namely closed-form KL at , exact reparameterisation, no Möbius singularities, and a controlled approximation error, is the load-bearing contribution. The OOD result in Exp 9 is the sharpest empirical sign that the geometry is doing something the Euclidean baseline cannot do.
What doesn’t work. Every architectural lever I tried to strengthen the in-distribution depth signal either created a trade-off (Exp 4: MSE versus ), introduced a shortcut (Exp 6: representation collapse), or got absorbed by the reconstruction loss (Exp 5, Exp 7). My reading of that pattern is simple: Euclidean reconstruction pressure erodes hyperbolic structure because good reconstruction does not require good geometric alignment.
A speculative path forward, not evidence. Replacing Euclidean MSE with a geodesic reconstruction loss on would couple reconstruction directly to the hyperbolic metric and might make geometric alignment a prerequisite for low loss rather than a side effect. That is a hypothesis, not a result.
7. Assumptions and Limitations
Taken in rough order of how much each point matters:
Single-seed main tables. Experiments 1, 2, 4, 5, 6, 7, 8, 9 report single training runs. Exp 3 (5 seeds, ) is the only variance estimate, and it shows that the single-seed differences of elsewhere are within seed noise. The OOD result () especially needs multi-seed replication before I would cite it confidently.
MSE floor . The observation noise in the tree MDP is 0.05, so the per-dimension floor is . The recurring value 0.405 across Exps 2, 5, 6 is far above this floor, so cross-model MSE comparisons are informative here.
Unverified mechanism. The drift-term explanation for why aligns with depth requires that deeper nodes have higher fibre mismatch on average. That is plausible for typical random-walk trajectories on the tree, but I did not measure it directly.
No hyperbolic-VAE baseline. The baseline comparison is versus Euclidean Gaussian only. Existing hyperbolic alternatives, such as wrapped normals (Nagano et al., 2019) and Poincaré VAEs (Mathieu et al., 2019), were not run. Claims of “computational parity” are against Euclidean only, and the representation-quality results do not show that beats other hyperbolic distributions.
approximation error. . For and typical posterior widths this is not small, so the optimisation target is not geodesically correct.
Sign of . Exp 3 reports , not . Cross-seed sign consistency, which is crucial for the “geometric inductive bias” claim, is inferred from the drift-term mechanism but not measured.
GRU architecture. The GRU treats as a flat Euclidean vector, with no inductive bias toward using for depth or for branch. An architecture with attention over hyperbolic representations, or a genuine hyperbolic recurrence, might produce qualitatively different results.
Synthetic, fully-balanced tree. The tree MDP is maximally hierarchical. Real environments have weaker, irregular, and potentially non-tree-like structure. Whether helps there is untested.
Compute parity is claimed, not measured.
8. Code and Reproducibility
→ View source code on GitHubAll experiments are implemented in PyTorch. The hrssm library contains the distribution with closed-form KL (validated against Monte Carlo, relative error 0.005%), the -ary tree MDP with OOD depth support, and all world model variants. Experiments 1–6 run in h_rssm_gpu.ipynb; Experiments 7–9 run in experiments_v2.ipynb, both Kaggle-compatible.
The three formulas needed to reproduce the key results:
- KL: , as given above.
- Reparameterisation: , (coupling must be preserved).
- Gradient attenuation diagnostic: .
9. References
- Ganea, O., Bécigneul, G., & Hofmann, T. (2018). Hyperbolic neural networks. NeurIPS.
- Gu, A., Sala, F., Gunel, B., & Ré, C. (2019). Learning mixed-curvature representations in product spaces. ICLR.
- Hafner, D. et al. (2019). Learning latent dynamics for planning from pixels (PlaNet). ICML.
- Hafner, D. et al. (2023). Mastering diverse domains with world models (DreamerV3). arXiv:2301.04104.
- Mathieu, E. et al. (2019). Continuous hierarchical representations with Poincaré variational auto-encoders. NeurIPS.
- Micheli, V., Alonso, E., & Fleuret, F. (2022). Transformers are sample-efficient world models (IRIS). ICLR 2023.
- Nagano, Y. et al. (2019). A wrapped normal distribution on hyperbolic space for gradient-based learning. ICML.
- Nickel, M., & Kiela, D. (2017). Poincaré embeddings for learning hierarchical representations. NeurIPS.
- Sarkar, R. (2011). Low distortion Delaunay embedding of trees in hyperbolic plane. Graph Drawing.
Appendix: Derivations
A.1 Normalising Constant of the Horospherical Gaussian
The unnormalised density w.r.t. the Riemannian volume form is:
Step 1 (integrate over at fixed ).
This is a -dimensional Gaussian integral with variance per dimension:
Step 2 (the key cancellation). The volume form contributes . Multiplying:
The -dependence of the -integral cancels exactly against the volume form. The remaining integral is purely over :
This is independent of and , which is exactly what I need for closed-form KL divergences.
A.2 Closed-Form KL Divergence
Let and .
The log-density w.r.t. is:
The KL divergence is .
Taking the difference of log-densities:
Height KL. Taking over (which marginally is ):
Combined with for the part ():
Fibre terms. Expand . Taking conditioned on , using :
Second cancellation and the drift term. Taking over for the second part:
Since , the moment generating function at gives:
This is the drift term. Combined with the contribution for (which is ) and :
Assembling all terms:
All three terms are to compute.
A.3 Reparameterisation and Gradient Flow
Sampling. Draw and :
Correctness. The marginal of is by construction. The conditional is:
which matches from the definition. The coupling is fully differentiable.
Gradient attenuation. The gradient of the decoder loss w.r.t. passes through , but w.r.t. it passes through . The expected magnitude of this gradient amplification factor is:
by the MGF of a Gaussian at . When , gradients from the fibre reconstruction are amplified into and can destabilise training, which is the gradient attenuation diagnostic reported in Experiment 2.
A.4 KL Approximation Error
The is not the Riemannian Normal . To quantify the discrepancy, consider the isotropic case , , , and compare with whose density w.r.t. is proportional to .
In the upper half-space, the geodesic distance from the origin satisfies:
The density exponent is , so it agrees with to leading order. The discrepancy arises from higher-order terms in the geodesic distance expansion. A Taylor expansion gives:
The leading coefficient grows quadratically with . At , : error . I do not think this is negligible for large or large posterior widths, and I treat it as the main theoretical limitation of as an approximation to the Riemannian Normal.
A.5 MGF Identity and Drift Term Stability
The drift term involves , which can grow without bound as . In practice, a clamp at is applied before exponentiation to prevent KL overflow during early training when posteriors are wide.
The full drift is bounded by:
After warmup, posteriors narrow and , so and the drift naturally weights fibre mismatch by , which penalises shallow nodes more than deep ones. This is the mechanism I rely on when I say that high fibre mismatch pushes upward and produces positive .
A.6 Coordinate Change from to
Step 1 (starting model). Start from the standard upper half-space model
with metric and volume form
Step 2 (change of variables). Define
Because is a smooth bijection with smooth inverse , this is a global diffeomorphism in the vertical coordinate, so (hence can range from to ).
Step 3 (differentials).
Step 4 (metric substitution). Substitute into :
Step 5 (volume-form substitution). Use the Jacobian determinant of :
hence
and therefore
So the parametrisation is not a new model. It is the standard upper half-space model written in log-height, or horospherical, coordinates.